
Project Title: Knowledge Extraction from Archival Lab Notebooks
Seeking: Undergrad
Opportunity Type: Paid
Time commitment: Approximately 10-15 hours per week
Application Deadline: Rolling until filled
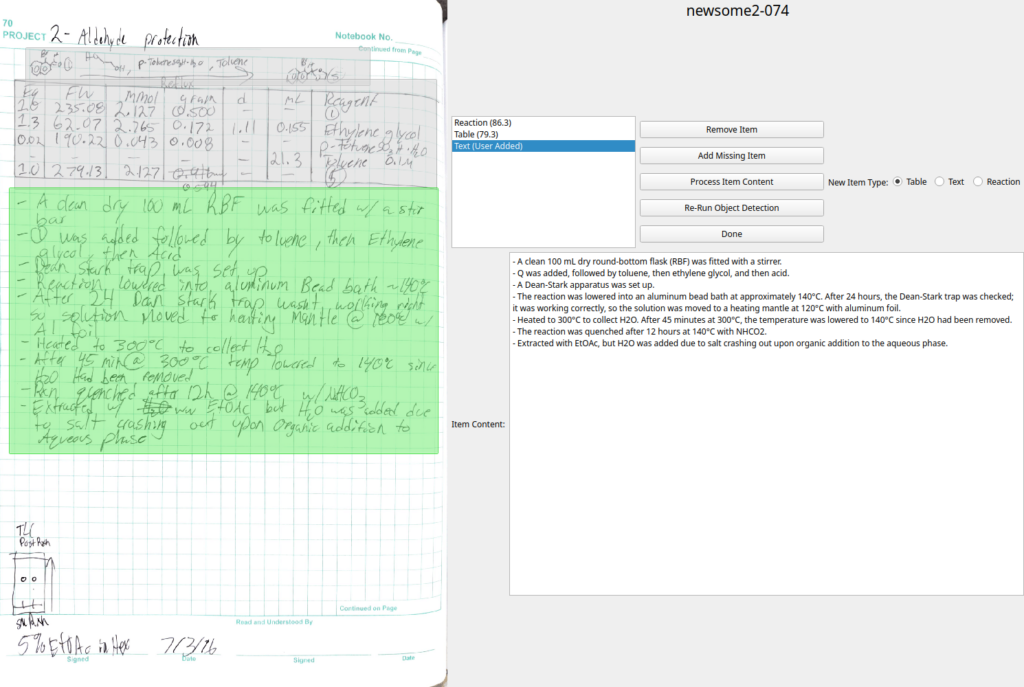
The Drexel Metadata Research Center (MRC) is seeking an undergraduate researcher to contribute to an applied image analysis project. This project is part of a larger NSF-funded initiative called the Institute for Data Driven Dynamical Design (ID4). The institute has an overarching goal of revolutionizing the design and fabrication of advanced active and dynamic materials by unlocking new scientific insights from underutilized digital data repositories.
As part of the ID4 collaboration, Drexel MRC is working with chemists at the University of Central Florida to study digital scans of paper lab notebooks. These notebooks document the synthesis of crystals known as metal/covalent-organic frameworks (MOFs/COFs). The primary objectives of this project are:
- To automatically extract the contents of experiments detailed in the notebooks,
- To design a machine learning compatible vectorized/graph-based representation of notebook contents,
- And to use this representation to perform document clustering analysis to answer scientific questions using the information contained within the lab notebooks.
Examples of scientific questions we are ultimately hoping to answer include:
- What is the progression of training in crystal engineering of MOFs, COFs, and related materials, and can progress be discerned automatically via these notebooks?
- When is a student properly trained at chemical syntheses of both organic and solid-state compounds?
- Are there any yet undiscovered patterns in the experimental properties documented in the notebooks that could differentiate successful experiments from those that failed?
For this undergraduate research position, there are a few different aspects of the project on which you could work based on your interests, with a primary focus on improving automated content extraction from the scanned pages. Potential work includes:
- Automatically removing “noise”/errant artifacts from the bounding boxes of segmented entries in order to improve subsequent optical character recognition. An example of this would be designing an auto-encoder (or similar) to remove portions of synthesis equations that were sometimes drawn too close to the table written below them.

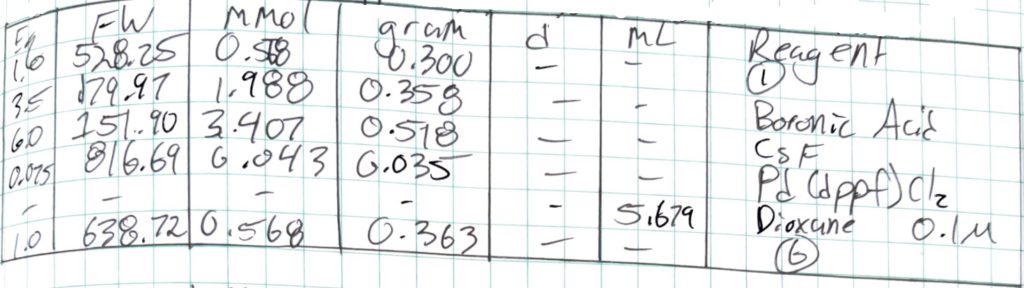
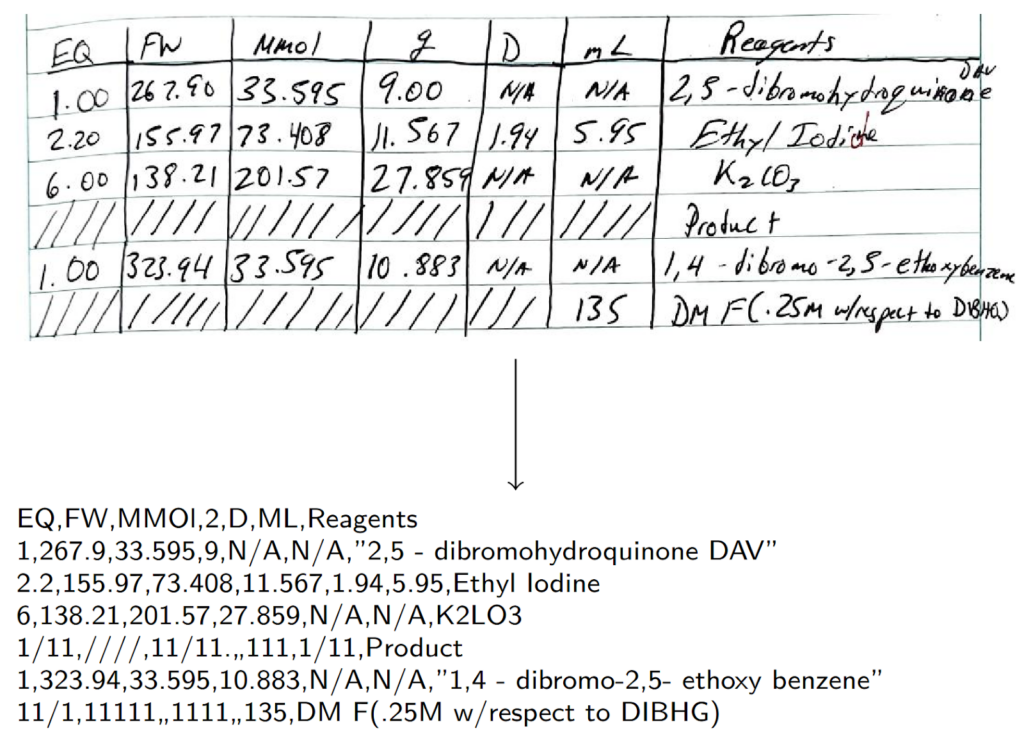
- Investigate the viability of using existing open source tools to automate the conversion of synthesis equations to a standardized textual representation.

- Explore the use of natural language processing techniques and/or large language models to maximize the accuracy of content extraction from tables and text blocks within the notebooks.
Additional resources on the project
How to Apply
Interested applicants should email their resume to PhD student Joel Pepper: jcp353@drexel.edu, and Professor Jane Greenberg: jg3243@drexel.edu.
Applicant Qualifications
- Required: Proficiency in Python programming.
- Desirable:
- Familiarity with PyTorch and working within the Linux command line.
- Previous experience working on project(s) involving machine learning, natural language processing, and/or image analysis is a plus.